Netify have released our 2024 SD-WAN comparison blog article
Learn more about comparison of SD WAN and SASE Cybersecurity with the Netify Learning Center.
Find articles and helpful resources about any of the following:
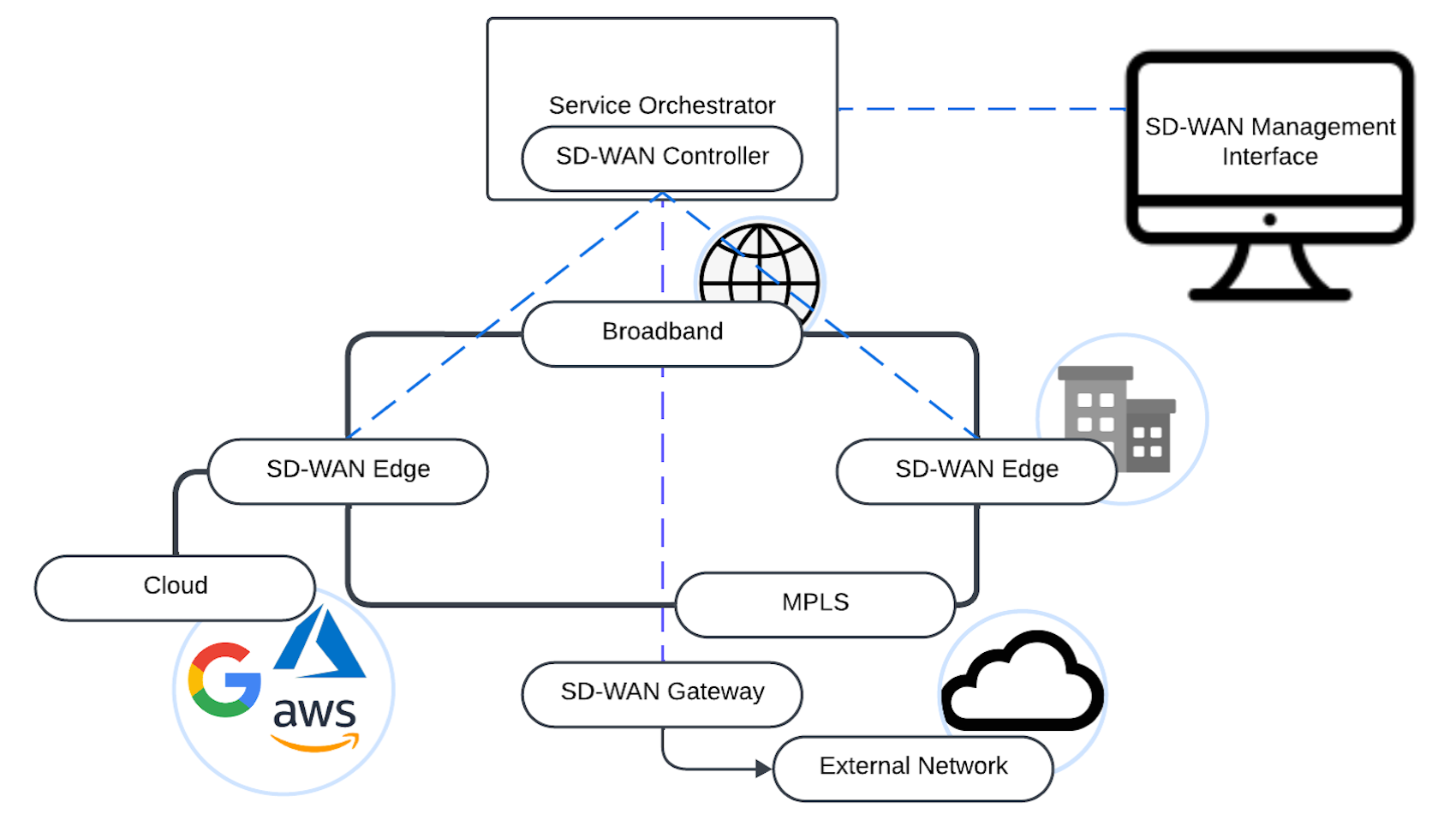
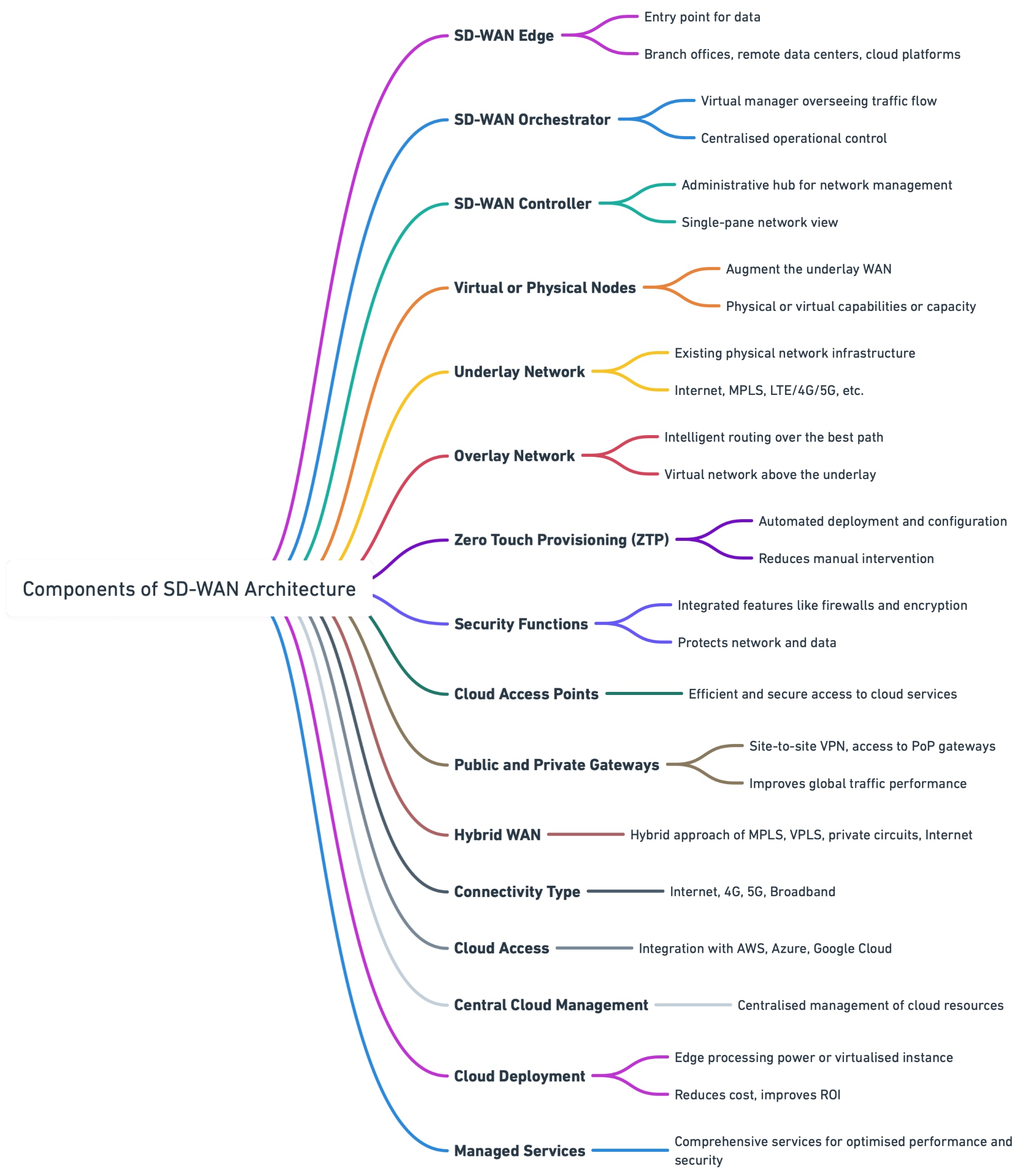
What is SD-WAN? Software-Defined Wide Area Networking (SD-WAN) is a better way for businesses to manage their network across different locations. This is achieved by leveraging a combination of transport services, such as broadband, LTE/5G and allows a secure connection between users and ... Read More
Introduction Read More
Fortinet is a globally recognised leader across cybersecurity solutions, the company has made significant strides in the Secure Access Service Edge (SASE) market. With their integration of security and network features, Fortinet offers a platform designed to meet the complex demands of most ... Read More
SASE Zero Trust: Implementing the Model for Enhanced Network Security Embracing SASE and Zero Trust: A Strategic Roadmap for IT Decision Makers SASE and Zero Trust are key security concepts for modern systems. SASE defines a singular cohesive security approach across an organisations system and ... Read More
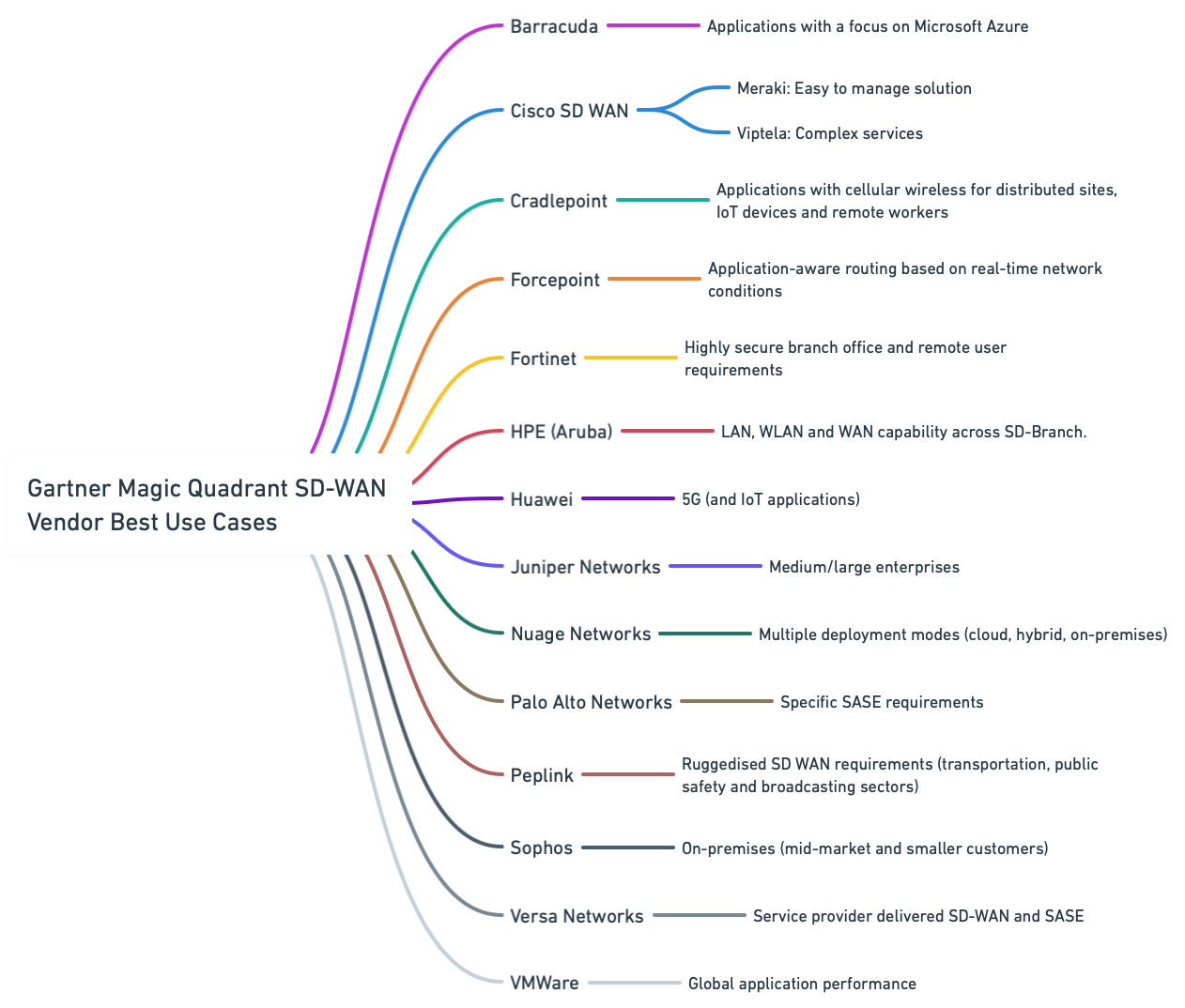
Prior to researching SD-WAN vendors and managed service providers, IT teams are required to understand the criteria to use when evaluating and comparing solutions. In 2024, evaluation criteria is firmly centralised around cyber security, specifically SASE (Secure Access Service Edge) and SSE ... Read More
Netify.com content has been written and fact checked by one of our SD-WAN or SASE Security writers. Netify.com only uses AI tools for researching content, analysing data and creating tables. We never publish any AI written content without human intervention. By reading Netify content, you can be ... Read More
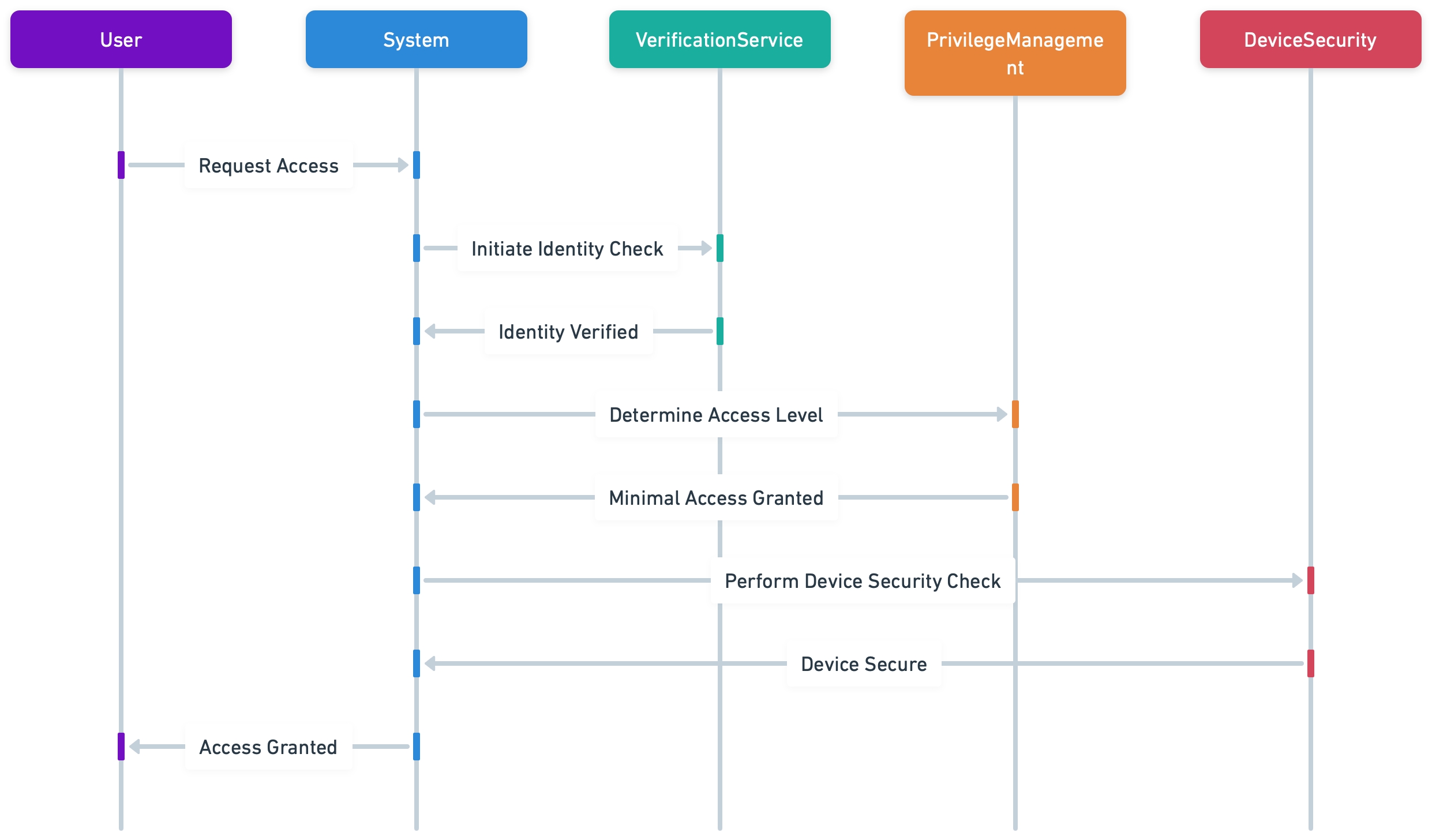
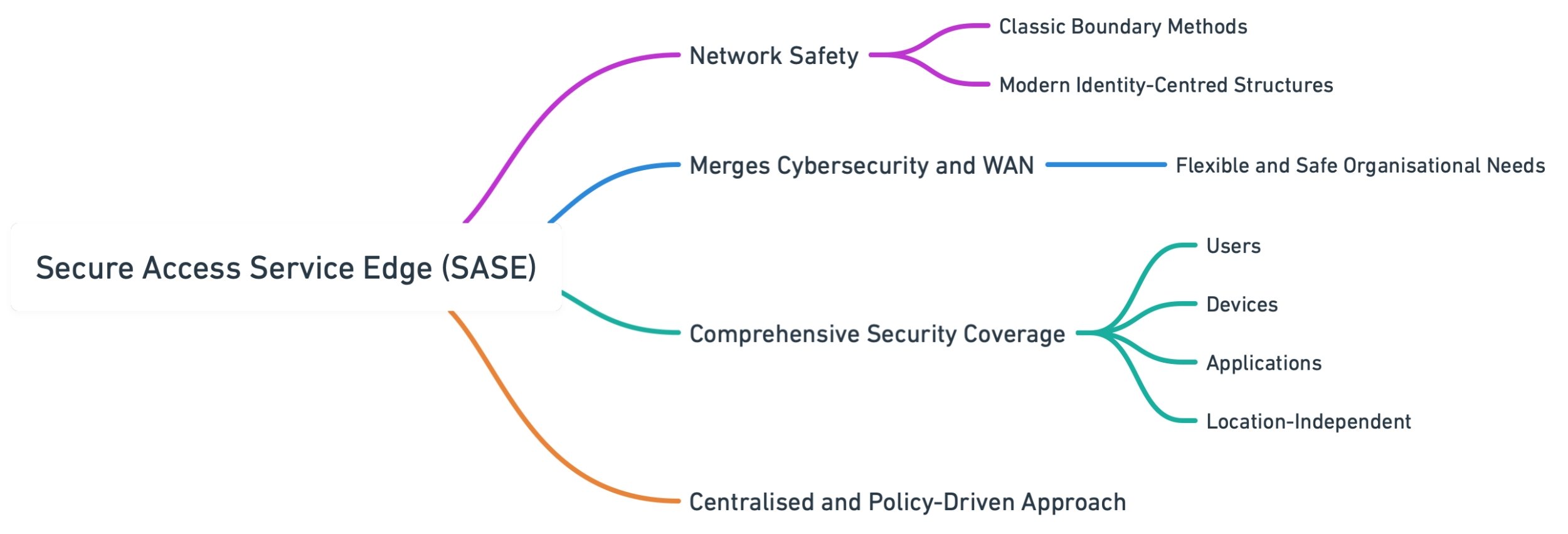
Secure Access Service Edge (SASE) brings significant change to how companies build network safety, mixing classic boundary methods with modern identity-centred structures. SASE merges cybersecurity solutions with Wide Area Network (WAN) capabilities to support the flexible yet safe needs of ... Read More
As new technologies and services are developed, the way that we secure our increasing digital infrastructure mustn't be overlooked. With hybrid and flexible work becoming the norm, a dependency on applications and data being accessed from anywhere is vital and legacy security solutions are simply ... Read More
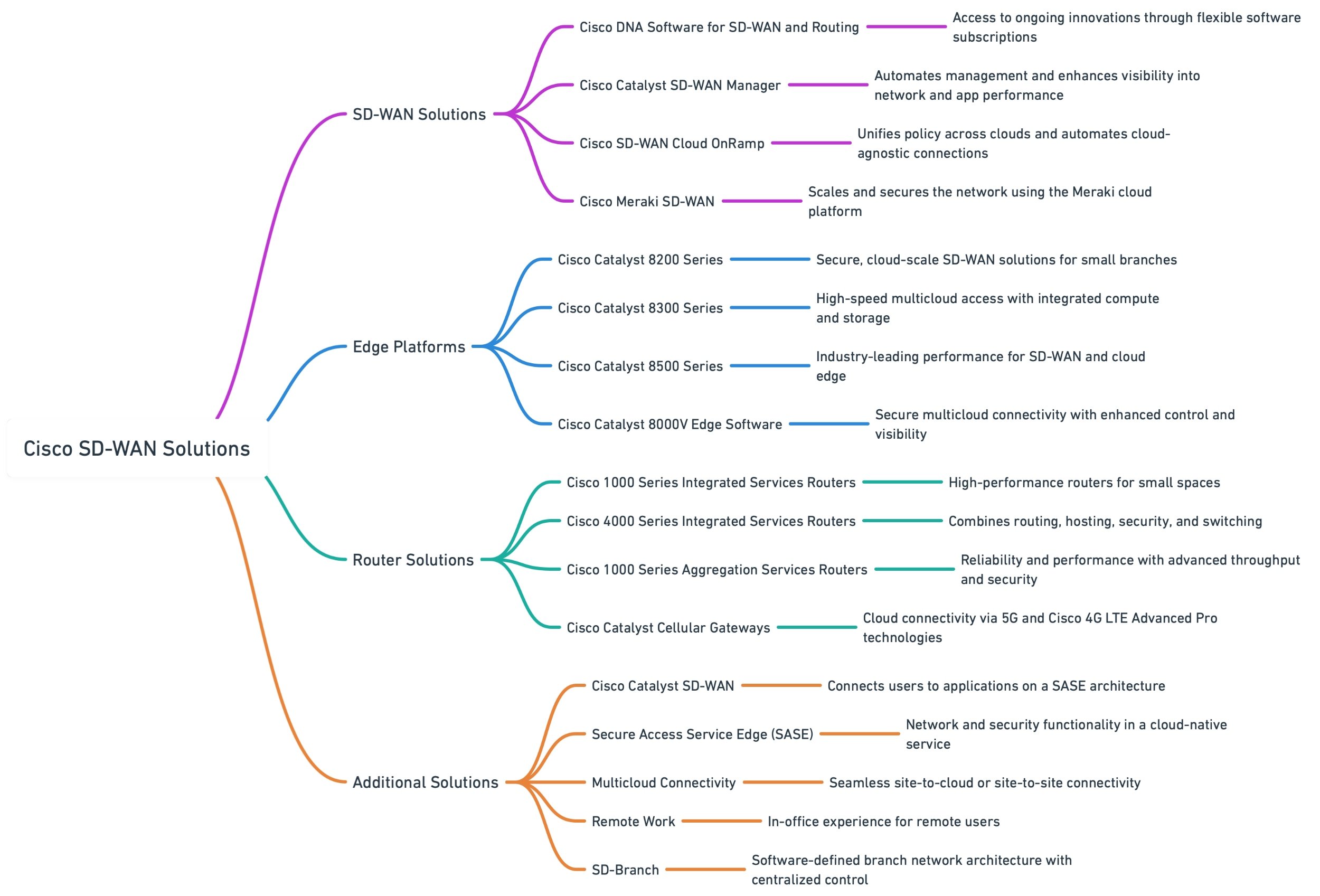
In this article, we provide an overview of Cisco's SD-WAN solutions with a focus on technical features and integration of technologies. The content aims to discuss how Cisco are delivering their SD-WAN solution as part of their fully featured SASE and SSE Cybersecurity solutions. Read More
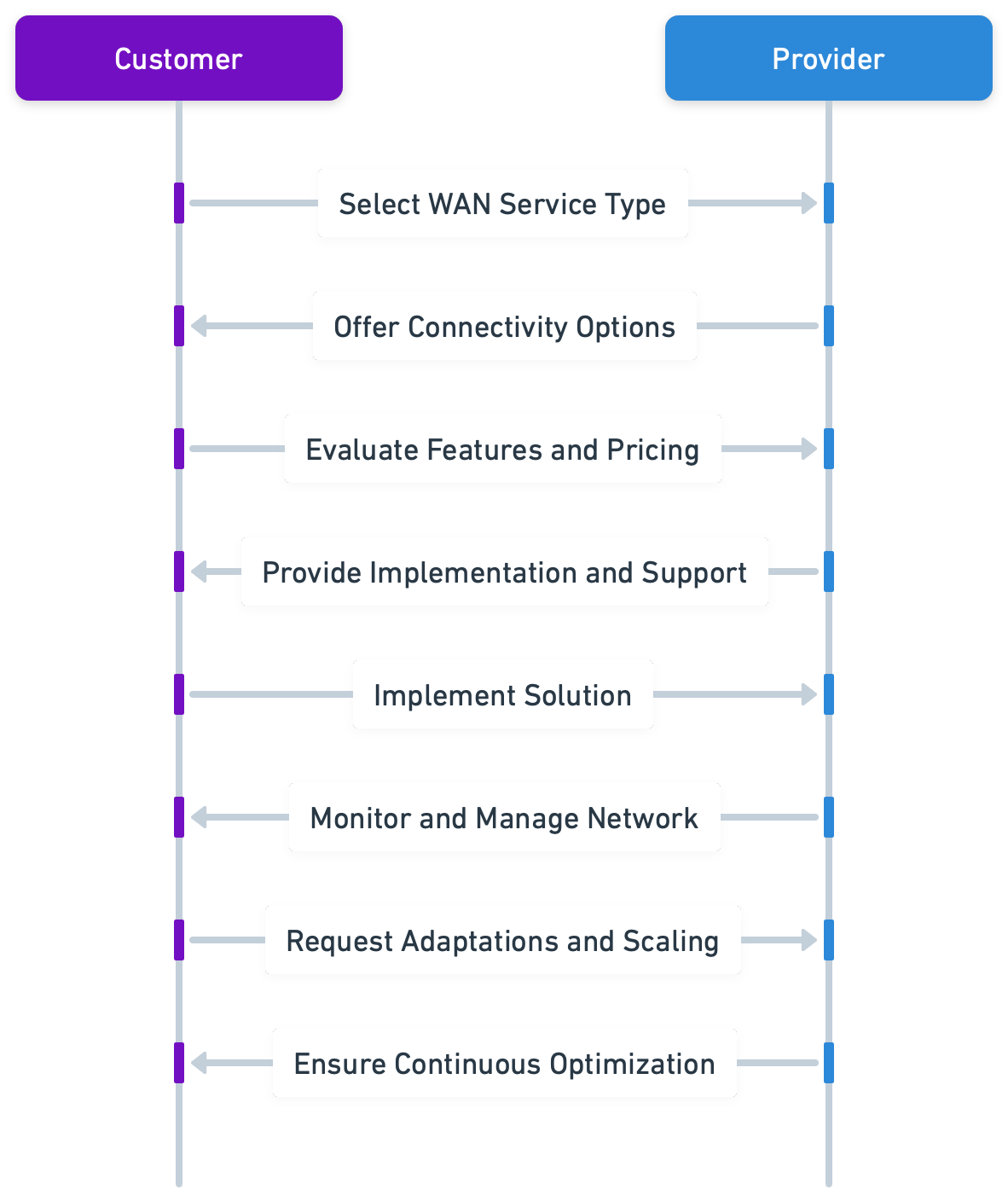
SD-WAN as a Service: The Future of Managed Network Solutions WAN as a Service (WaaS) enables organisations to utilise the cloud when procuring fully managed or co-managed WAN infrastructure. The WaaS model vastly simplifies network management and scales easily to accommodate an increasing reliance ... Read More